Amazon Elastic Beanstalk allows you to quickly provision the infrastructure needed for an entire application without the hassle of managing the configuration of EC2 instances, Elastic Load Balancers, Auto Scaling, and many other AWS services. Elastic Beanstalk also automatically monitors these resources and provides a simplified view into your application’s health.
One area of confusion with Elastic Beanstalk’s simplified health view is how to interpret the health colors and statuses. With only basic health monitoring enabled, your application health is presented using one of four colors: Green, Yellow, Red, and Grey.Green health status generally means that your application is healthy based on the default health checks.
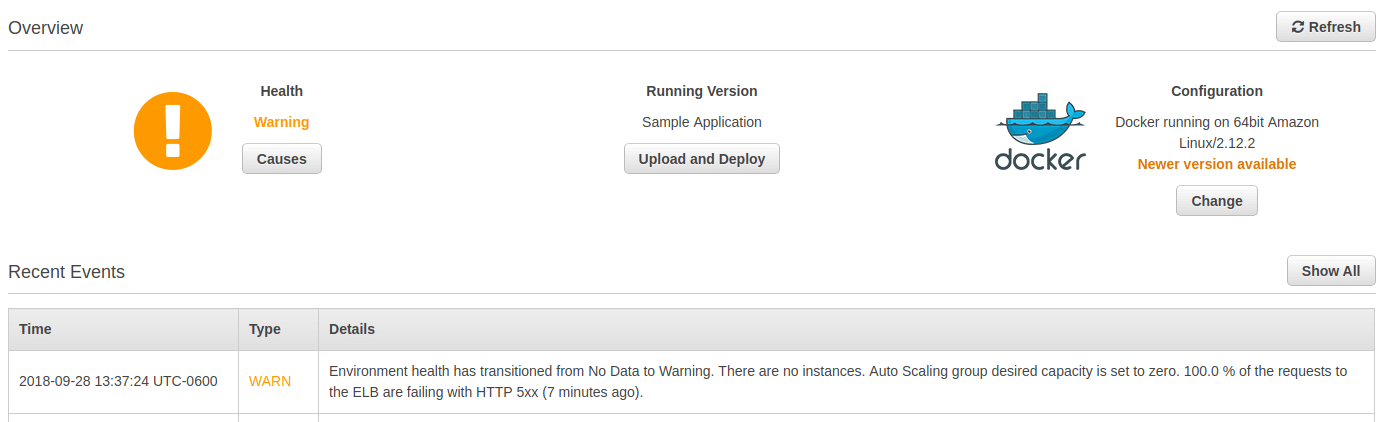
Yellow means that your environment has failed some health checks and requests to your environment may be failing. You should look at application metrics and logs as quickly as possible to prevent health from degrading to Red.
Red means that your environment is failing many health checks, some resources may be unavailable, and requests to your application are likely failing. In some cases, your environment will be Red if your application is scaling up. In this case, just ensure that requests are completing successfully and that there is no impact to your end users. If your application is not scaling up, then an outage is likely already in progress and needs to be addressed ASAP to minimize user impact.
The Grey health status can be tricky. The AWS Documentation describes Grey as "Your environment is being updated". This is only partially accurate. Your environment will be Grey during initialization, but can also be Grey if its status is unknown to Elastic Beanstalk or if the environment became so unhealthy that it is no longer monitored.
The health colors present some obvious problems. You would not expect your an environment that was scaling up to have the same health status as an environment that is completely broken. You also would not expect the same color to represent a newly initialized environment as well as one that is so broken it cannot be monitored. Without further context, it’s impossible to determine the actual state of your application from the health colors.
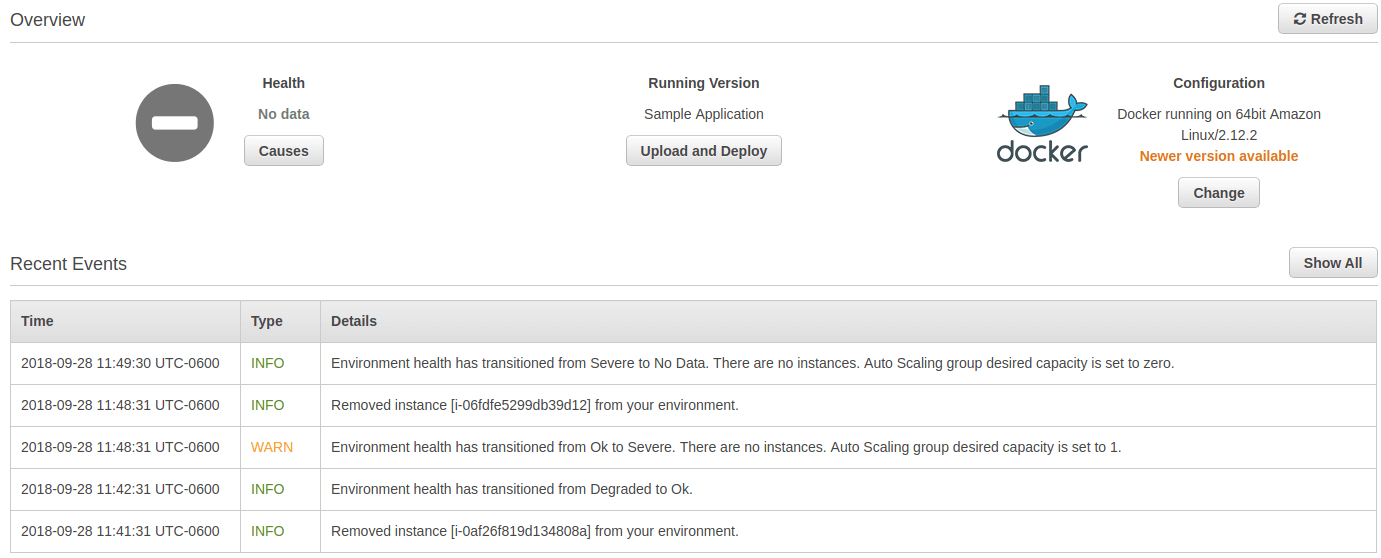
Scaling down to 0 EC2 instances sets the environment health to Red (Severe), creates a Yellow (Warning) event, and then changes to Gray (Unknown) when the operation is finished... ?!?
Two hours later (without any interaction), the application is now in a warning state…
This is where Enhanced Health Monitoring comes in. With Enhanced Health Monitoring enabled, Elastic Beanstalk reports health at a more granular level and exposes CloudWatch metrics to help you investigate application issues. Most importantly, with enhanced monitoring, Elastic Beanstalk will add a text status to the health colors. Unfortunately, these statuses show that the color system is not a straightforward scale. Below is the scale ordered by severity:
Grey (Suspended) - Your application has had such severe health issues Elastic Beanstalk is no longer monitoring it
Red (Severe) - An instance or environment is reporting a very high number of request failures
Yellow (Warning) - An instance or environment is reporting a moderate number of request failures
Red (Degraded) - An instance or environment is reporting a high number of request failures (this is lower severity because scaling actions can cause it)
Grey (Unknown) - The health agent has not reported enough data on an instance yet
Grey (Pending) - An operation is in progress on an instance within the command timeout (for example bootstrapping the environment)
Green (Info) - An operation is in progress on an instance
Green (Ok) - Instances and environments are passing health checks
With enhanced health monitoring enabled, the Elastic Beanstalk agent will collect additional metrics and publish them to Cloudwatch. There are many interesting metrics at the environment and instance level, but we’ve narrowed it down to a few that are great candidates for CloudWatch alarms and can help you troubleshoot issues.
ApplicationRequestsTotal - The number of requests made to your application. Use this metric in combination with other metrics to determine if your application needs to be scaled to handle incoming traffic. The Sum and Average statistics will be most useful for this metric.
ApplicationRequests5xx - The number of requests that responded with a 5xx response code. These responses can be caused by timed out requests, no servers being available to handle the requests, unhandled exceptions in code, or errors in other services that your application uses. Check your application logs and load balancer logs to determine the cause of these errors. The Sum statistic is most useful for figuring out how many total requests failed.
ApplicationLatencyP50 and ApplicationLatencyP99 - The median and 99th percentile for application latency can be useful to gauge your application’s performance under different workloads. The expected values for either of these metrics depends heavily on your application’s requirements. When querying CloudWatch for these values, use the Average statistic. Comparing the median latency over time can help you determine the latency that most of your users experience. For alerting, the 99th percentile metric tends to be more indicative of issues that would be appropriate for a CloudWatch alarm.
LoadAverage1min - When monitoring individual instances, load average can help you determine if an instance is overwhelmed. A good rule of thumb is to take this value and calculate the normalized load average from it by dividing the Average by the number of CPU cores the instance has. If that value is greater than 1, consider scaling your application or distributing some of the load to other instances. If the value is greater than 2, then that instance is likely to have performance issues during peak traffic.
RootFilesystemUtil - If the root filesystem runs out of space then the Enhanced Health monitoring agent may fail. To prevent this, you can clean up large files that are no longer in use, add EBS volumes, or modify your launch configuration to have a larger RootVolumeSize. The most useful statistics will be Average and Maximum. If you create a CloudWatch alarm for this metric, set a threshold of about 90-95% disk space utilized, depending on the size of your root volume.
With enhanced monitoring enabled, and some basic CloudWatch alarms set up, you're at a great starting point for monitoring your Elastic Beanstalk application. Blue Matador goes beyond metrics and static thresholds to proactively find all the problems vexing your web app.
{kind=link}
{kind=link}